Once you have your connection to or from video, you need to choose a way to get that data from or to the disk. This varies from trivial to hard depending on your platform's memory system and your disks. Try out the methods on this page in order. When you've got a solution that works on your target platforms, stop: you're done!
Since we're focusing on disk I/O, we'll assume you have the operations to get and release video fields described in Basic Uncompressed Video I/O Code.
Many of the sections below use the terminology defined in Concepts and Terminology for Disks and Filesystems.
{
p = videoport_open(direction, 20, 0);
fd = open(filename, O_RDWR|O_TRUNC|O_CREAT, 0644));
for(;;)
{
videoport_wait_for_space_or_data(p);
f = videoport_get_one_field(p);
rc = write(fd, f->pixels, nbytes);
videoport_put_one_field(p, f);
}
}
The most obvious way to get video from disk is to "just read it:"
{
p = videoport_open(direction, 20, 0);
fd = open(filename, O_RDONLY, 0644);
for(;;)
{
videoport_wait_for_space_or_data(p);
f = videoport_get_one_field(p);
rc = read(fd, f->pixels, nbytes);
videoport_put_one_field(p, f);
}
}
Working code for this is in justdoit.c.
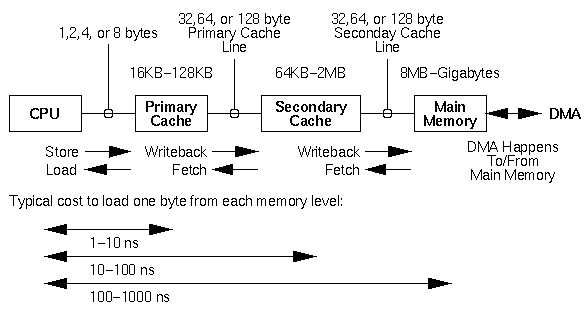
This standard usage of read()/write() is called buffered I/O because it will go through the UNIX kernel's buffer cache. When you read() data, the kernel will DMA the necessary disk data into the kernel buffer cache, and then copy the requested data into your buffer. When you write() data, the kernel will copy your data into the buffer cache and return to you. The cached data will eventually be DMAed to the disk.
DMA (Direct Memory Access) is the process by which a hardware device (like a video I/O system or a SCSI disk controller) pulls data out of main memory or puts data into main memory. Usually the CPU can do other things while hardware DMAs are in progress, even things that use main memory. The kernel buffer cache is just an area of main memory which the kernel manages. The term "kernel buffer cache" does not refer to:
However, video disk I/O is not a normal UNIX application. It requires unusually high bandwidths.
On platforms where the CPU and memory system are fast enough to copy video data between the buffer cache and your buffer in real-time, you can use buffered I/O. If you are writing code for high-end and possibly even mid-end SGI systems, you should try this technique before spending time on the more elaborate techniques below.
When you're trying out buffered I/O, keep in mind that SGI systems can copy data much more efficiently if the source and destination buffers are properly aligned, as described in Copying Data Quickly. You can assume that the kernel's buffers are 8-byte aligned. Therefore, the copy will be efficient if the pointer you pass to read() or write() is 8-byte aligned. Fortunately, malloc() returns 8-byte-aligned pointers, and entries in VLBuffers and DMbufferpools are always at least 8 byte aligned.
The kernel can bcopy() faster than you can from user-mode on some SGI systems, using some protected instructions. So actual buffered I/O performance may exceed the best user-mode bcopy() benchmark which you can cook up.
Even if your system has the juice for buffered I/O, we have found that sometimes the kernel's algorithm for when to discard buffered read data, and when to write back buffered modified data, is not ideal for video applications. You can control this decision somewhat with calls such as fsync() or fdatasync() and with various kernel tunable variables.
If buffered I/O works for you, then stop right here. You're done.
Direct I/O
On platforms where the CPU and memory system are not fast enough to
copy video data between the buffer cache and your buffer in real-time,
you need an alternative---direct I/O.
Direct I/O lets you bypass the buffer cache and its associated memory copy by providing buffers that the kernel uses directly as the target of a DMA operation. You use direct I/O by specifying the O_DIRECT flag to open(), or by enabling the FDIRECT flag using the F_SETFL fcntl(). Direct I/O works on local EFS and XFS filesystems.
In a way, direct I/O makes your disk system work like your video system. vlGetActiveRegion() and dmBufferMapData() point you directly to the area of memory into which or out of which the video hardware does DMA. So if you pass those pointers into direct I/O read(), write(), readv(), or writev(), you can move data between your video hardware and your disk hardware with no copies on the CPU.
A direct I/O write() will not return until the DMA operation has completed. Contrast this with buffered write(), which is little more than a copy into the buffer cache. A direct I/O read() or write() will always generate a DMA; the OS makes no attempt to cache read data.
You can access a file using both direct I/O and buffered I/O at the same time, and the kernel will automatically keep both views of the file consistent. For example, the kernel will invalidate a region of the buffer cache when you modify its underlying disk storage with direct I/O.
As you might guess from the section above, direct I/O puts the duty of meeting the hardware's constraints on you. The F_DIOIONFO fcntl() tells you what constraints you must follow for a given file descriptor:
{
int fd = open("filename", O_DIRECT|..., 0644);
struct dioattr dioinfo;
/* get direct I/O constraints for this fd */
fcntl(fd, F_DIOINFO, &dioinfo);
...
void *data = pointer to data you're going to read()/write();
int nbytes = size of that data;
/* verify data and nbytes for direct I/O read()/write() */
printf("buffers can be between %d and %d bytes\n",
dioinfo.d_miniosz, dioinfo.d_maxiosz);
assert(nbytes >= dioinfo.d_miniosz);
assert(nbytes <= dioinfo.d_maxiosz);
printf("buffers must be a multiple of %d bytes long\n",
dioinfo.d_miniosz);
assert((nbytes % dioinfo.d_miniosz) == 0);
printf("file position must be on %d-byte boundary\n",
dioinfo.d_miniosz);
assert((lseek64(fd,SEEK_CUR,0) % dioinfo.d_miniosz) == 0);
printf("memory buffer must be on %d-byte boundary\n",
dioinfo.d_mem);
/* uintptr_t is integer that's pointer-sized (see inttypes.h) */
assert((((uintptr_t)data) % dioinfo.d_mem) == 0);
read(fd, data, nbytes); or write(fd, buf, nbytes);
}
Working code that reads or writes video with direct I/O is in dio.c.Although you must open a raw device file without O_DIRECT, and although you cannot use fnctl(F_DIOINFO) on a raw device file, I/O to a raw device file has all the characteristics of direct I/O:
{
int fd = open("filename", O_DIRECT|..., 0644);
struct dioattr dioinfo;
int vector_chunksize;
int vector_memalign;
/* get direct I/O constraints for this fd */
fcntl(fd, F_DIOINFO, &dioinfo);
/* additional constraints for readv()/writev() usage */
vector_chunksize = max(dioinfo.d_miniosz, getpagesize());
vector_memalign = max(dioinfo.d_mem, getpagesize());
...
assert(NVECS <= sysconf(_SC_IOV_MAX));
struct iovec iov[NVECS] = desired pointers and lengths;
int totalbytes = 0;
/* verify iov[] for direct I/O readv()/writev() */
for(i=0; i < NVECS; i++)
{
void *data = iov[i].iov_base;
int nbytes = iov[i].iov_len;
assert((((uintptr_t)data) % vector_memalign) == 0);
assert((nbytes % vector_chunksize) == 0);
totalbytes += nbytes;
}
assert(totalbytes >= dioinfo.d_miniosz);
assert(totalbytes >= vector_chunksize); /* redundant, but hey */
assert(totalbytes <= dioinfo.d_maxiosz);
assert((lseek64(fd,SEEK_CUR,0) % dioinfo.d_miniosz) == 0);
readv(fd, iov, NVECS); or writev(fd, iov, NVECS);
}
As you can see, the memory alignment and I/O size constraints become
at least as strict as the system's pagesize (4k or 16k depending on
the platform and OS release). The file position and maximum I/O size
constraints are the same.Working code that reads or writes video with direct I/O readv()/writev() is in vector.c.
As of IRIX 6.3 and 6.4, readv() and writev() are not supported for raw device files. If this is important to you, please contact your local support office.
Here's how you finesse that problem:
The VL_MGV_BUFFER_QUANTUM control [and its MGC counterpart] is provided so an application can specify the "block size" that should be applied to a video unit. (The video unit is a field or frame, depending on the capture type). For example, setting this control to 512 will cause the frame or field size, as reported by vlGetTransferSize, to be rounded up to a multiple of 512. This control should be set to a multiple of the block size returned by fcntl(fd, F_DIOINFO, ...), or to the optimal block size for the device.When VL_MGV_BUFFER_QUANTUM is set to a value other than 1, the video data is padded at the end with random values. Consequently, it is important to use the same value for VL_MGV_BUFFER_QUANTUM on capture and on playback. This can be a problem if a file is copied from one device to another, where the allowable block sizes differ. It is recommended that the control be set to a common multiple of the allowable sizes. For example, 4096 satisfies most devices. Otherwise the file may need to be reformatted.
((offset_within_group % vector_chunksize) == 0).This is because each vector in the reader's readv() request is constrained to satisfy
((iov[i].iov_len % vector_chunksize) == 0).This often means that each item must be padded out to that boundary in the file.
But if your application produces files which the user could transport to a different type of SGI machine, move to a different disk, or access after installing a new OS release, the directio constraints at write and read time may not match. You must choose a set of constraints which works for all target configurations.
Unfortunately, there are no published guarantees from SGI about the range of many of the direct I/O constraints or the system page size. We recommend that you use these constraints in your video writing program:
It is unlikely that you will run into trouble with these values, but we can offer no guarantee: we recommend that you continue to call fcntl(fd, F_DIOINFO, &dioinfo) and getpagesize() and use those constraints or fall back to buffered I/O if they are stricter than those above.
Our suggested constraints can be wasteful of disk space and bandwidth. If you want to cut down on the waste, here are some tips:
If your application has the further constraint that your files need to be transportable to non-SGI machines, but still read efficiently on SGI machines, then we recommend you write the data to a file yourself and then use the SGI Movie Library to add a QuickTime header to the file. We'll describe this process in detail in Getting Raw Data in and out of the Movie Library. Despite its humble origins, the QuickTime file format is now mature enough that you can write video fields or frames anywhere in the file and tell QuickTime where they are. Furthermore, a file reader can query the location of each field or frame and read the data itself.
If your application reads files with video, and wants to see if it can use direct I/O readv() or writev() on the entire file, it needs to scan the file offset of each field in the file. For many applications this will work fine. For applications which handle particularly long files, this might be a problem. Some developers have requested some kind of single tag which the application could read once which told it about the worst case alignment and padding of all of the video fields in a particular QuickTime track. SGI may recommend that Apple add such a tag to the QuickTime file format, but we'd still like more feedback from developers about what exact information that tag needs to carry.
Alas, there is a hitch. Devices such as video, disk or graphics DMA to or from main memory. They are not aware of the state of the data cache. This can lead to cache coherency problems.
{
videoport_wait_for_space_or_data(p);
videofield *f = videoport_get_one_field(p);
pixel *p = field->pixels;
int i;
for(i=0; i < pixels_per_image; i++)
*p++ = something;
videoport_put_one_field(p, f);
}
The for loop will cause the CPU to issue lots of stores. When we get
to videoport_put_one_field(), some of those words have been pushed out
to main memory (because the cache filled up), but some of them may
still be in the data cache (only a few SGI data caches are
write-through). The video device will DMA out of main memory and use
some of the wrong data.
{
videoport_wait_for_space_or_data(p);
videofield *f = videoport_get_one_field(p);
pixel *p = field->pixels;
int i;
for(i=0; i < pixels_per_image; i++)
something = *p++;
videoport_put_one_field(p, f);
}
When we get to the for loop (during which the CPU issues lots of
loads), the video device has DMAed our field into main memory. But
the data cache may have been caching the data at any of the locations
*p from before the DMA, and so we will load "stale" data instead of
our new field. Worse yet, we may have stored into any of the
locations *p before the DMA, and so if the cache later fills up, the
processor will write back the stale data to main memory, destroying
the data for our new field in main memory.
For the other SGI systems, the cost of the software I/O coherency operations varies greatly. For a region of memory which is bigger than the secondary data cache (which video fields or frames often are), the worst-case cost of a writeback-invalidate ranges from 2.6ms on an R5000PC O2, to 4.1ms on an R5000PC/SC Indy, to 4.2ms on an R5000SC O2, to 7.3ms on an R4400SC Indy, to 8.1ms on an early-model R10000 O2. You can measure the writeback-invalidate cost on your system using dmGetUST(3dm) and cacheflush(2). For video/disk applications, this cost will generally appear as system or interrupt time (the yellow or red bar of gr_osview).
That is just the hint you give by calling vlBufferAdvise(VL_BUFFER_ADVISE_NOACCESS) or passing cacheable==FALSE to dmBufferSetPoolDefaults(). Specifying NOACCESS will do the right thing on all platforms (including those with I/O cache coherency hardware, where the right thing may be nothing!). We recommend ignoring the return value. On some platforms where the NOACCESS feature is not supported (Indigo2 IMPACT R10000 for example), vlBufferAdvise() will fail, which is pretty much the best the program can do on that platform.
IRIX 6.2 exhibits a vlBufferAdvise() bug which is visible on sirius platforms (Onyx, Challenge). This bug may have been present in releases before IRIX 6.2. If you request VL_BUFFER_ADVISE_ACCESS or if you do not call vlBufferAdvise() (since ACCESS is the default), this should introduce no performance penalty on high-end systems with I/O cache coherency hardware. But the IRIX 6.2 VL will perform software cache coherency operations anyway, harmlessly but wastefully burning up CPU cycles. The workaround is to call vlBufferAdvise(VL_BUFFER_ADVISE_NOACCESS) on sirius platforms even if you intend to access the data. This workaround will only work on sirius, and may not work on releases later than IRIX 6.2.
On platforms without I/O cache coherency hardware, there are some cases where a buffer can be accessible (mapped) but references to that buffer bypass the cache (uncached). This is only supported on some SGI platforms. Each load or store instruction must touch main memory, and may be very expensive. You can achieve this mode by passing cacheable==FALSE and mapped==TRUE to dmBufferSetPoolDefaults() or using cachectl(2) on a non-VL buffer. The mode is not available with VLBuffers. This mode may be useful in cases where you want to touch only a few words per field (for example if you want to parse the VITC out of each field) but write the rest to disk. Stay away from this if you want cross-platform software.
Don't forget that these caching optimizations only apply when you're doing direct disk I/O. The OS will need to touch your data with the CPU when you're doing buffered disk I/O.
For VLBuffers and DMbufferpools this is already done---these buffers are always resident. For non-VL buffers, you can use the mpin() system call to assure that a buffer always has underlying physical pages.
Many of SGI's drivers (video, disk, and graphics) have fast path checks which skip the whole residency procedure if the buffer is marked as pinned.
If field-at-a-time direct I/O works for you, then stop right here. You're done.
If you still do not get enough disk throughput, then you need to start thinking about how your requests to read and write video data are performing on your disk system. You are probably not keeping all your disk drives busy reading or writing all the time, which means you're wasting potential throughput. Read on!
While you are recording or playing back uncompressed video, a disk in your system which is not reading or writing data is probably doing one of these things:
Many of the sections below use the terminology defined in Concepts and Terminology for Disks and Filesystems.
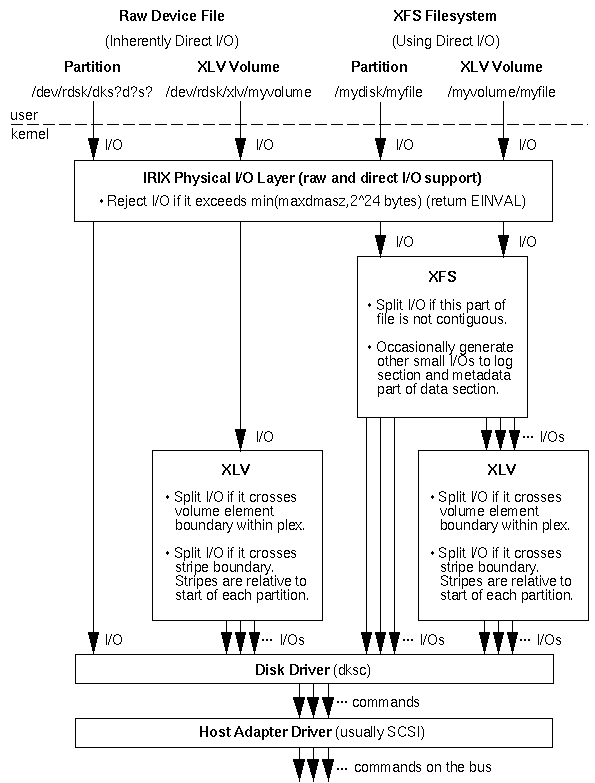
If you've read this far then you're using direct I/O or raw I/O. Here are all the layers that could be involved in your I/O, from highest to lowest:
You will learn more about each layer as you read on.
Disk Seek, Disk Retry, and Disk Recal Issues
The worst case seek time of modern disks ranges from 5 milliseconds to
tens of milliseconds, so you must make sure that your disk accesses
are sufficiently close that the seek cost doesn't rob you of your
needed throughput. We'll examine the sources of disk seeks from
the bottom up.
When your computer issues a read or write request to a disk over a bus, it specifies the starting location for the operation as a "logical block number." The drive is actually divided up into "physical sectors," and the drive firmware maps logical block numbers to physical sectors. Normally, it will map logical blocks of increasing address to contiguous physical sectors. But real disk drives have surface defects (up to 1% of a drive's sectors may be bad before it is considered broken). The firmware of many drives will automatically remap logical blocks which would point to defective sectors to other (sometimes distant) sectors. This can introduce extra seeks. You can query the drive for a map of defective physical sectors, but there is no sure-fire way to determine how the drive will map any given logical block number to a physical sector.
When a drive hits a bad sector which it has not previously marked as defective, it will retry the operation a number of times (0 or higher) which you can control with fx. In many cases, the error is recoverable with one retry. The default on SGI-shipped drives is to retry at least once. After a certain drive-specific (and not queryable) number of failed retries, the drive will assume the head is miscalibrated and perform a thermal recalibration operation. If you set the drive retry count high enough, retries and recals together can prevent any useful disk activity from proceeding on the disk for up to several seconds. If the number of retries you requested all fail and the drive still cannot return the correct data (read case) or write the data with possible sector reallocation (write case), then the I/O operation you issued will fail with an error like EIO. If you crank down disk retries in order to bound the worst-case disk I/O execution time, be aware that your I/Os may fail much more often. You can only disable retries on disks which you access with raw device files or XFS realtime subvolumes, since the data and log sections of XFS filesystems must remain consistent for the filesystem to work (unrecoverable errors an XFS log section cause nasty console messages and/or system panics, for example).
Drives on some SGI systems are configured to perfom recals once every 10-20 minutes, regardless of whether a failure has occurred. These periodic recals prevent useful disk activity for a maximum of 50ms for today's drives (4 or 5 times that much for older drives). The newest SGI configurations only recalibrate when a sector read or write actually fails.
From now on, this document will ignore seeks due to remapped blocks (it will assume logical blocks map contiguously on to physical sectors), retries, and recals. In practice, some apps use the default retry count and successfully ignore the effect of these anomalies, and some place requirements on the condition of the disk.
An obvious way to avoid seeks at the partition and logical volume level is to access their raw device sequentially. As we will see in the discussion of disk commands below, when you access a disk partition or XLV data subvolume in a sequential manner using its raw device file, you are accessing logical blocks on the underlying disks in a sequential manner.
If there is some serious error on your SCSI bus such as a timeout or a SCSI reset, or if there is some failure in a particular SCSI device such as unit attention, media error, hardware error, or aborted command, the dksc driver (which manages access to partitions by you (/dev/rdsk/dks?d?s?), XLV, and XFS) will retry an I/O several times. If all the retries fail, your I/O will fail. These serious failure conditions can incapacitate your bus or device for seconds. They do not occur in normal operation, so this document will ignore them.
Finally we get to XFS. When you write to a file in an XFS filesystem, the filesystem decides where to place the data within the raw partition or volume, and it may be forced to fragment a file. Currently there is no XFS mechanism to guarantee contiguous allocation of a file. One practical way to create contiguous files is to start with an empty filesystem, and pre-allocate the amount of contiguous space you will need in one or more files using mkfile(1) or the F_RESVSP fcntl(). Unlike F_ALLOCSP, this XFS fcntl doesn't zero out the allocated space and so is fast. After preallocating contiguous files, you can use your disk normally. This method is similar to the raw partition method, since part of your disk becomes dedicated to one use, but the dedicated part can be accessed by any normal UNIX program without going through the awkward /dev/rdsk mechanism.
You can use the xfs_bmap(1M) tool or the F_GETBMAP and F_FSGETXATTR fcntl(2)s to check whether and how a specified XFS file is fragmented across your disk.
There is currently no XFS filesystem reorganizer (fsr). The fsr program rearranges existing file data to create large contiguous free sections. EFS, the previous SGI filesystem, supported fsr, but the days of EFS are numbered. We don't recommend building a product around that filesystem. If your application requires filesystem reorganization or additional contiguous file support from XFS, please post questions and your data to an SGI newsgroup or contact your local field office.
Unless otherwise specified, the rest of this document will assume that the vast majority of your disk access is sequential, and so seek time is never a significant limiting factor. Some of the optimizations we will describe here only work under that assumption.
The OS accomplishes file I/O by issuing commands to the relevant disks. A command is a data transfer between the computer (the host) and one disk on one bus. During a command, the computer reads from or writes to a sequential set of logical blocks on the disk. Each command looks like one DMA on the host side and involves various bus acquisition and data transfer procedures on the bus side. The host adapter is the piece of hardware on the host which implements that DMA by communicating over the bus. At any given time, the host can be executing multiple commands to different disks, on a single bus or multiple busses.
When you use buffered I/O, the OS chooses when to issue disk commands and how large they are. With direct I/O (including I/O to a raw device file, which is inherently direct):
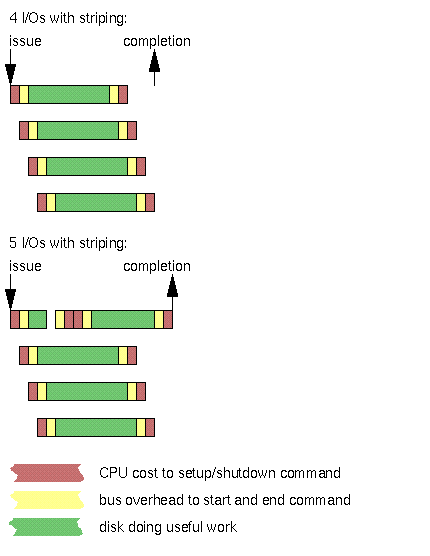
But there are other CPU costs, and there are the bus usage costs. Some of these costs scale linearly with the size of the command. Some of these costs are fixed per command. If your system has significant per-command fixed costs, you can increase your overall data throughput if you make your commands as few and as large as possible. This simple diagram assumes each of your I/Os generates one command to the same disk:
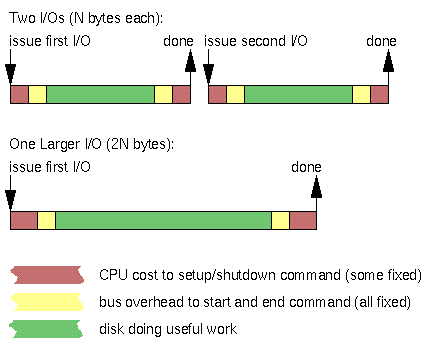
In the upper case, we pay several extra fixed CPU and bus costs to shut down the first I/O and set up the second I/O.
This diagram is not to scale. For uncompressed video disk applications, where each command transfers hundreds of kilobytes and where you have eliminated the cache coherency and residency operations, the CPU and bus setup costs are typically a tiny fraction of the useful work.
Because of uncertainties in UNIX process scheduling, we may also waste some additional time, shown as a gap between the two I/Os, between when the first I/O completes and when our application runs and issues the second I/O. These delays may be a significant fraction of the useful work done by each command. You may be able to reduce this average time with some of the hacks described in Seizing Higher Scheduling Priority.
Say you can somehow assure that the costs between the two I/Os (bus overhead to complete and issue commands, CPU overhead, UNIX process scheduling) will be no more than a few tens or hundreds of microseconds. In some cases, this small delay in the host response may trigger a multi-millisecond delay in the disk response which is called a missed revolution. We'll discuss missed revs more when we talk about disks below.
As the diagram shows, combining the two commands into one reduces the overall cost and brings us to our result sooner. We also eliminate one command boundary, and thus one opportunity for a missed rev.
How can you increase your command size in video disk I/O programs? Typical video applications have their video data stored in field- or frame-sized buffers, so it would seem that roughly 300k or 600k is the greatest possible I/O size. Fortunately, UNIX offers an extremely simple I/O interface called readv() and writev() which allow you to do one contiguous I/O to a file from several buffers which are not contiguous in memory. As of IRIX 6.2, readv() and writev() are supported on direct I/O file descriptors. As discussed in detail in Direct I/O above, the direct I/O constraints become a little more strict when using direct I/O readv()/writev(), but they are still within the parameters of VLBuffers and DMbufferpools. So your video recording or playback program can do disk I/O in multiples of V fields or frames.
Working code that reads or writes video with direct I/O readv()/writev() is in vector.c.
Choosing V can sometimes be tricky. The readv() and writev() calls can accept at most sysconf(_SC_IOV_MAX) vectors. This is 16 on all systems as of 9/3/97, but it could get larger on future OSes. One of the directio constraints, dioinfo.d_maxiosz, limits the total number of bytes per readv()/writev(). Ideally, you would want the largest value of V which satisfies these conditions. But V is also equal to the number P used in determining how much memory buffering to use in your videoport, as described under "How Much Memory Buffering Do I Need?" in Basic Uncompressed Video I/O Code. A high value of V may lead you to allocate a prohibitively large amount of memory, depending on your application and target platforms. You need to choose the best tradeoff.
UNIX geek note: the requests which we call I/Os are actually called uio_ts or buf_ts inside a UNIX kernel, depending on the level at which they occur. The distinction is not important for this discussion. The requests which we call commands are called scsi_request_ts inside IRIX.
This document makes many simplifying assumptions about your XLV volume, which you can read about in Concepts and Terminology for Disks and Filesystems. This diagram leaves out the kernel buffer cache since we are talking about direct I/O (and since raw I/O is inherently direct).
All raw or direct I/O requests pass through a layer called physio. This is the layer which does the cache and residency operations described above. You should have already rendered these operations harmless if you've read this far in the document. The physio layer imposes an overall hard limit on I/O size of min(maxdmasz, 2^24 bytes). This guarantees that the I/O will not exceed hardware and software limits in lower layers. One of the direct I/O constraints (dioinfo.d_maxiosz) gets its value in part from this limitation. The maxdmasz kernel tunable variable defaults to 1MB. In some cases (most likely with disk arrays), you may want to issue I/Os bigger than 1MB. To do this, apply the maxdmasz tune shown in Hardware/System Setup for Uncompressed Video I/O. The 2^24 value comes from the number of bits available in the SCSI command SGI uses for read and write commands (nope, encapsulation is not a technique used in a UNIX kernel!).
In the next two sections, we'll follow your I/O through the XFS and XLV levels to see the cases where it can be split into several I/Os or generate other I/Os.
When you use an XFS filesystem instead of a raw device file, the kernel occasionally needs to update the filesystem's log section and the metadata in the filesystem's data section. The kernel will automatically generate these I/Os. Their frequency depends on the frequency of your I/Os. Although these log and metadata updates involve a miniscule number of bytes compared to your video data, they may generate the occasional seek on your disks and so their cost may be significant. There is no easy way to judge what kind of performance impact they will have. Some developers use a rule of thumb that the log and metadata updates will eat up 10% of the throughput achievable from the raw device file, but we're not so sure this is a good rule of thumb. For example, if you use XLV to place your log section on a different set of disks, the impact of the log updates may become negligible.
Given our assumptions from that document, the mapping from logical subvolume to plex is one-to-one, and there is only one plex (no redundancy) for each logical subvolume. So this level passes your I/O through unchanged.
A plex may contain several volume elements. If your I/O spans two or more volume elements, XLV will split it up. Since your volume elements should be vast in size compared to a typical I/O, we will assume this event is rare enough to be insignificant, and ignore it.
If your volume elements are single partitions, the mapping from volume elements to partitions is also one-to-one.
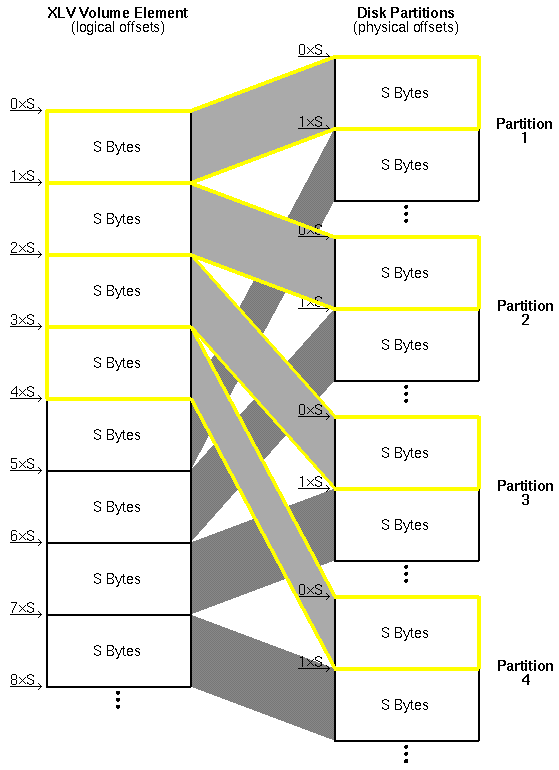
The interesting stuff happens when you have a striped volume element with partitions on different disks. XLV will split your I/O into stripe-unit-size pieces and execute the pieces concurrently on each of the volume element's partitions. It is crucial to understand exactly where XLV will split your I/O. Say you have a striped volume element with N=4 underlying partitions, and a stripe unit of S bytes. XLV will use the following fixed scheme to map logical positions within the volume element to physical positions on the volume element's partitions:
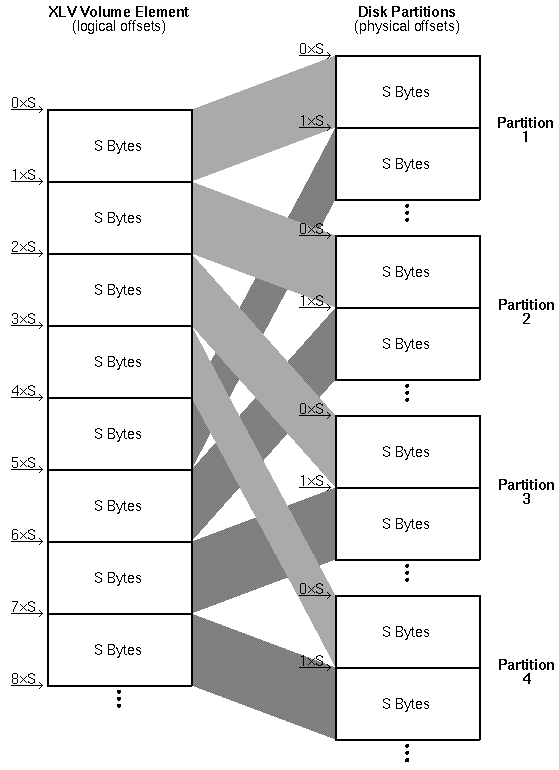
As you access the volume element from beginning to end, you access:
Note that the beginning of a stripe unit occurs at offset 0*S, 1*S, 2*S, ... within each partition, and the beginning of a stripe occurs at offset 0*N*S, 1*N*S, 2*N*S, ... within the volume element.
With this fixed addressing scheme, the striped combination of N disks should give you an overall throughput that is N times the throughput of the slowest disk in the stripe (since your I/O does not complete until all the I/Os it generates have completed).
To make your app use the striped volume element as efficiently as possible, you want each of your I/Os to generate the fewest and largest possible I/Os on the underlying disks.
The first obvious thing is that this scheme will never generate an I/O larger than S bytes. So if you choose S very small (say 16k), then your I/O will get split up into an enormous number of small I/Os and you will lose performance in bus and CPU overhead.
You want to choose the largest value of S that will still give you parallelism, given your application's usage pattern. For example, say your app reads or writes one 256k field at a time using direct I/O. If you choose S==1MB, then each of your I/Os will execute on at most two, and usually one, of the disks in the stripe set! You will not have achieved the desired N-fold throughput increase.
For an application which issues one direct I/O (read(), write(), readv(), writev(), ...) of W bytes at a time, a good value of S to use would be W/N. This would tend to give you the smallest number of largest-sized I/Os to your underlying disks.
Things are more complicated for an application that does asynchronous I/O, which will be defined below. In this case, we need a more general definition of W: "the number of bytes of I/O which the application has outstanding at any given time." Then the formula is the same as above.
Depending on the constraints of your application, you may be able to tweak W by changing your app, or tweak S by telling your users to create their logical volume in a certain way, or both.
Another performance issue on striped volumes is stripe alignment. Say you perform an I/O of size N*S. How many I/Os will that generate?
If your I/O is stripe-aligned, then you will generate N=4 I/Os (each generated I/O is outlined in yellow):
These I/Os will execute in parallel on each disk, and you will have hopefully achieved a near-fourfold performance improvement.
But if your I/O is not stripe-aligned, you will generate N+1=5 I/Os (the first four I/Os are outlined in yellow, and the fifth is outlined in green for clarity):
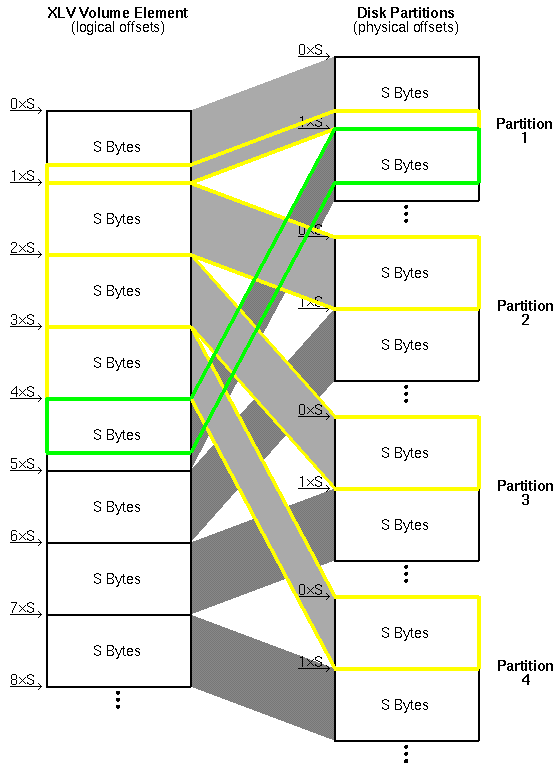
Remember that your I/O (ie, your call to direct I/O read(), write(), readv() or writev()) will not return until all the commands it generated have finished. If there is a significant fixed cost associated with commands in your system, the fact that there are two, smaller commands on disk 1 may hurt your overall performance:
How can you assure that your I/Os are stripe aligned?
But it is likely that your desired N*S will exceed the blocksize limit of 64k for uncompressed video disk programs, since you'll likely have four or more disks (N>=4) and want commands way bigger than 16k (S>=16k). This is where the XFS real-time section comes in. When you create an XFS filesystem with a real-time section, you specify an extent size for the real-time section which is a multiple of the data section's blocksize. Unlike the blocksize, the extent size maxes out at a healthy 1GB. For any given file in the real-time section, XFS will then guarantee that an offset within the file that satisfies (offset % extentsize == 0) maps to an offset within the real-time section's underlying XLV realtime subvolume that also satisfies (offset % extentsize == 0).
Therefore, if you place your video data in an XFS realtime section, you can guarantee that your I/Os will get split up and executed in the most parallel fashion on the underlying disks.
In Hardware/System Setup for Uncompressed Video I/O, we specified some platform-specific tunes you could apply to your system, and promised to explain when they were useful later. Now is the time:
XLV striping is the most obvious example of this. An I/O to a striped volume gets split up into several commands which execute concurrently on several disks. We discussed XLV striping above.
You can exploit parallelism even when issuing commands to one disk. Since your CPU and your bus are separate entities, you can often increase your throughput by overlapping the CPU part of one command with the bus part of another command, as shown here (as above, we assume that each of your I/Os generates one command to the same disk):
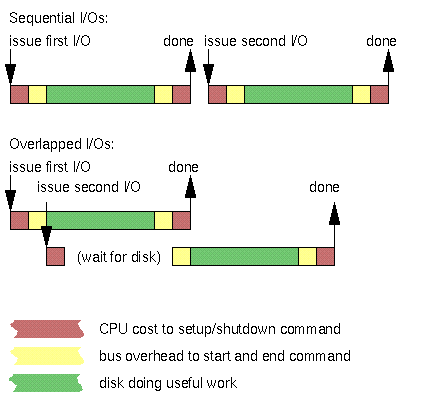
This is called asynchronous I/O. In this case, you still end up paying the same CPU cost and the same bus cost, and you still have the same gap between the start of each I/O due to UNIX process scheduling. But you take advantage of your ability to pay some of these costs simultaneously, and so you get to your result sooner.
Another way to think of it: asynchronous I/O lets your app give the OS advance warning of upcoming commands. The OS can use this advance warning to pay its fixed per-command setup costs while the bus and disk are busy. Then, when the bus and disk become free, the OS can issue the next command most efficiently. As we'll see later, the OS can often extend this advance warning into the host adapter hardware layer, and you and the OS can extend the advance warning all the way down to the disk itself using something called disk command tag queueing. The lower you go, the more opportunities for parallelism you can exploit. With the right combination of methods, you can even reduce or eliminate missed revolutions. We'll describe these lower-down methods of parallelism later.
If you've read this far in the document, then you're using direct I/O or raw I/O. These forms of I/O do not return until all the commands they generate have completed. To take advantage of asynchronous I/O for video, you will need a way to have multiple direct or raw I/O requests outstanding. In other words, you need a way to tell the OS what I/O you are going to issue next while one is currently executing.
The POSIX party line way to do this is the aio library (man aio_read(3), aio_write(3)). The aio method is less code for you, but aio lacks a selectable file descriptor which you can block on until the I/O completes (instead, it uses signals or other-threadly callbacks), and aio does not support readv()/writev().
You may instead want to roll your own asynchronous I/O code by issuing I/Os to the same file simultaneously from separate sproc(2) threads or pthreads. If you can only open() the file once, you need to use pread()/pwrite() from each thread so that the seek and read/write operation are atomic in each thread. Otherwise, we recommend that you open() the file once per thread so that each thread has its own file descriptor with its own current file position ("file pointer," in lseek(2) lingo). The dup(2) and dup2(2) system calls will create another file descriptor with the same current file position; you do not want to use them. Because there is no preadv() or pwritev(), opening the file once per thread is the only way you can use readv()/writev() and asynchronous I/O together.
Working code that reads or writes video with direct I/O readv()/writev() in an asynchronous manner (not using the aio library) is in async.c.
Be warned: there are few things that will twist, complicate, add bugs to, and reduce the readability of your code more expertly than asynchronous I/O. To understand why, consider that asynchronous I/Os do not necessarily complete in the order you issue them. Think about how your application manages buffers of video data now. For example, if you are using the classic VL buffering API (see What Are the SGI Video-Related Libraries?), the vlPutFree() and vlPutValid() calls do not take a VLInfoPtr argument. They assume that you want to free or enqueue the oldest item that you have dequeued or allocated (respectively). To get the most out of asynchronous I/O, you will want to keep each of your threads or aiocb_ts busy, so you may need to free or enqueue items in a different order than you dequeue or allocate items (respectively). In Basic Uncompressed Video I/O Code, we presented a wrapper around the classic VL buffering API which gave you this ability, albeit with some memory waste. This shortcoming of the classic VL buffering API is one of the main reasons why the DMbuffer APIs exist. The DMbuffer APIs lets you free or enqueue items in any order with optimal memory usage, since you pass in a DMbuffer handle to dmBufferFree() or vlDMBufferSend().
Even with the DMbuffer APIs, asynchronous I/O is messy because it involves coordination between processes. We strongly recommend you investigate all other options before paying the development cost for asynchronous I/O.
This performance difference can be significant for video disk I/O applications in terms of missed revolutions, which we'll describe below.
Once a read or write command between the computer (the host) and a disk begins, the disk will begin to shuttle chunks of data at bus speeds between the host and some RAM on the disk itself. Typical modern disks have a few hundred kilobytes of RAM. Disk arrays may have significantly more. A disk will only occupy the bus when it is shuttling one of these chunks to or from the host. Then the disk will let go of the bus ("disconnect" in SCSI terms) and begin the much slower process of transferring data to or from its media. Several commands to different disks on the same bus can be in progress at once. Each disk takes turns refilling its RAM (in the write case) or emptying its RAM (in the read case) over the bus. On the host side, the host adapter implements the DMA issued by the OS using these chunks of data shuttling in and out on the bus.
This diagram shows one complete write and read command:
The row marked "command" represents the interval between when the OS programs the host adapter to initiate the command to the disk on the bus and when the host adapter notifies the OS that the disk has reported the command complete. The upper arrow shows how the host DMAs into (write command) and out of (read command) the fast RAM on the hard drive. The lower arrow shows how the (much slower) media side of the disk writes from the RAM to the media (write command) or reads from the media to the RAM (read command). The row marked "disk RAM fill level" shows how the disk's RAM fills and empties as the host and media sides of the drive access it.
How does the disk decide when to request more data from the host (write command) or push more data to the host (read command)? This is controlled by a set of drive parameters which you can set with fx, including a high (read command) or low (write command) water mark and some bus ownership timeouts. Unfortunately, there is no way to query the size in bytes of the disk's RAM (the high and low water marks above are percentages). You have to get this data from the drive manufacturer.
Note that the drive holds the bus for only a small percentage of the command. You can create antisocial drives by disabling drive disconnect using fx, but this is unlikely to be useful for video disk I/O. We'll assume all your drives have disconnects enabled.
The row marked "command completeness on the disk's media" indicates what percent of the data for this command has actually been read from the media or written to the media. Finally, the row "media busy" is the really important one: it says whether the disk is actively reading or writing on the media. If we are forced to access the disk's physical sectors non-contiguously, then from now on we will also count time spent doing these seeks as "yes." If we're doing our job right, then this row will be "yes" all the time.
To put it another way, our job is:
You can see if these options are enabled on a disk using the label/show/all command of fx.
You can enable and disable these options on a disk using the label/set/ commands in fx. You must run fx in expert mode (-x) to do this. The label/set options in fx are extremely dangerous, so be careful when you use them not to hose your disk.
The disk may already be reading data off its media when the read command begins, if it has readahead enabled. When a disk with readahead enabled has just finished reading data off its media to satisfy a given read command from the host, it will immediately continue to read from the next location on the media, on the theory that the host is about to request that data as part of the next command. If the host is accessing the disk in a sequential manner (as is the generally the case for uncompressed video disk I/O), then readahead allows the disk to do non-stop useful work even though the host may not be able to react to the completion of one command by starting another one quickly. This diagram shows the optimization pictorially:
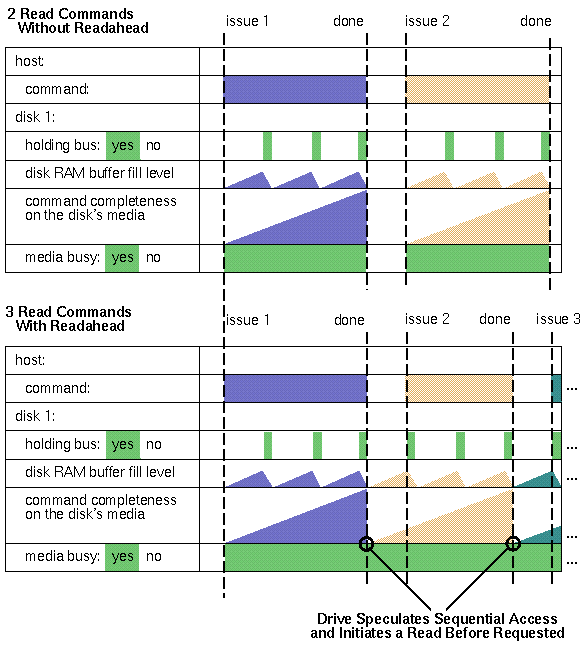
In this case, if the two commands are sequential, then there is no idle media time.
Readahead is on by default on all SGI-shipped disks. Some disks have fancy readahead algorithms which can track several different threads of sequential access.
In this diagram, the drive's RAM begins to accept data for a given command while it is still draining data to its media for the previous command. Some drives are not this smart, and will begin to request data just as soon as the media is done with the previous command. Either way, the host has some extra time to react to the completion of each command by issuing the next command without the media going idle. For smart drives, the host also has some extra time to react to the drive's request for data for the next command before the media goes idle.
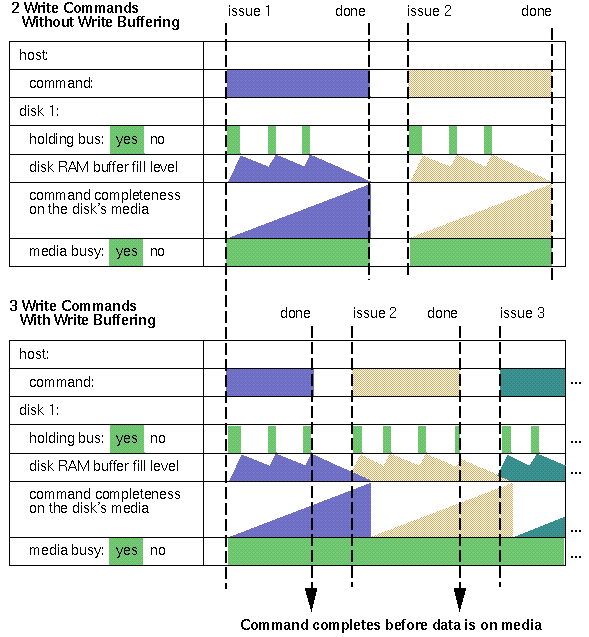
Like readahead, write buffering allows a disk to do non-stop useful work even if the host cannot immediately react to the completion of one write command by issuing the next write command.
Unlike readahead, write buffering has a nasty side effect. A disk with write buffering enabled can get into a situation where it has multiple write commands pending. There is no efficient way for the host to guarantee that only one write is pending at a time. The disk is allowed to reorder those writes (presumably to reduce seek time and increase throughput). That is, the disk need not modify the media in the order in which the commands were issued. If there is a power failure, it is possible that later commands made it to the disk media but earlier commands did not. This is a major problem for journalling filesystems such as XFS, which rely on the ability to guarantee the ordering of their write commands on the disk media to keep the disk in a consistent state at all times, even if a power failure occurs. XFS assumes that writes to any XFS data or log section will be ordered, and so disks containing those sections can not have write buffering enabled. Because of this clash, write buffering is disabled by default on all SGI-shipped disks. This assumption allows XFS to instantly recover a disk after a power failure, without a tedious fsck step. Writes to an XFS realtime section may be unordered, so disks containing only XLV realtime subvolumes may have write buffering enabled, since the realtime section contains no metadata.
But worry not: it turns out there is something just as good, command tag queueing, which works for all XFS sections and is enabled on all SGI-shipped disks. Read on!
Disk command tag queuing is superior to readahead in that the disk does not need to speculate about the next location to read from. If the host issues non-sequential reads, the disk immediately issues a seek rather than wasting time reading off the wrong location on the media.
Disk command tag queueing is superior to write buffering in that the host can enqueue new commands at any time (even before it could with write buffering), and the host gets notified when each command is done on the media.
The disk notifies the host when each enqueued write command has completed on the disk's media. Therefore, disk command tag queuing does not suffer the write ordering problem described for write buffering above. The host can guarantee write ordering by isuing special SCSI tagged commands that are marked as ordered, or by simply assuring that at most one command with ordering constraints is pending on the disk at any given time.
To understand missed revolutions, remember that most disk devices (including the insides of disk arrays) use spinning platters. A disk gets a chance to read or write a particular track only once per mechanical revolution. For a 7200 RPM disk, that's once every 8 milliseconds. Say you're doing 128k commands to a 6 MB/sec disk: each command takes about 20ms.
Consider these cases: