Concepts and Terminology for Disks and Filesystems
This case study uses the terminology from the most excellent
IRIX Admin: Disks and Filesystems IRIS InSight book by Susan Ellis,
Dany Galgani, and Gloria Ackley, which you'll find at the above link
and also in eoe.books.IA_DiskFiles. Refer to the "Logical Volume
Concepts" chapter for some good pictures.
Here we will summarize the terminology from that InSight book and fill
in many additional assumptions and facts that are relevant to this
case study.
This document ignores efs. This document ignores lv, which is an
obsolete efs-based logical volume scheme.
Disks and Partitions
A physical disk device that sits on a bus (usually a SCSI bus) and has
one bus ID is called a disk. Each hard drive inside
your SGI is one disk. A disk array is an external
device which may contain many hard drives, but looks like one disk
(has one ID) to a connected SGI machine. Internally the array may
have many of the concepts we'll describe below (striping, plexing,
etc.) but to the SGI, it's just one disk (usually a really fast one).
A disk enclosure or disk vault is an
external device which also contains disk drives, but merely acts as an
extension of your SCSI bus; each disk drive has a separate ID to the
SGI machine, and thus is a different disk.
You divide a disk into partitions with fx. You can
see how a disk is partitioned with prtvtoc or fx.
XLV Logical Volumes
Although you can access a partition directly, video disk I/O often
demands more storage or bandwidth than one disk partition can deliver.
In this case you use XLV to group many partitions together into a
logical volume using xlv_make. Here is the key example picture,
stolen outright from the IRIX
Admin: Disks and Filesystems IRIS InSight book:
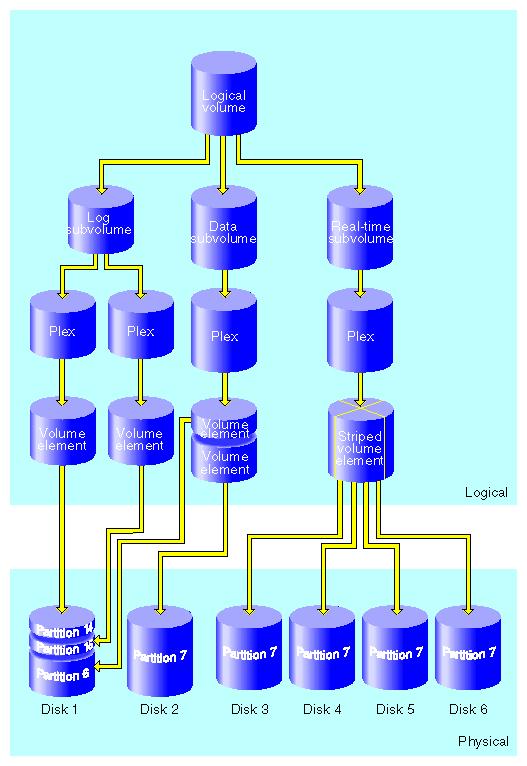
Your disks, divided into partitions, appear at the bottom of this
diagram. Like a file, a partition is an addressible
object: it has a size, and you can think of reading or writing at any
offset (or address) from zero up to its size.
The lower three layers of XLV work by taking a group of addressible
objects (partitions or other XLV addressible objects) and making them look like
one addressible object. Each layer maps the address
range of underlying objects into its own address range.
At the lowest layer of XLV, you group one or more partitions together
into an addressible object called a volume element.
- You can logically abut partitions by creating a
multipartition volume element, meaning that as you
access the volume element from beginning to end, you move across the
first partition from beginning to end, then the second partition from
beginning to end, etc. But this is boring.
- Much more interesting is to create a striped volume
element consisting of partitions on different disks, as is
done within the real-time subvolume in the diagram above. Striping
allows you to record and play uncompressed video, whose bandwidth we
described in How Big is Video?, even
when no single disk can sustain that througput. Say you have a
striped volume element with N partitions on N disks. If you were to
access the volume element from beginning to end one byte at a time,
you would access the first S bytes from the first disk, then the first
S bytes from the second disk, etc. until you ran out of disks. Then
you would access the second S bytes of the first disk, the second S
bytes of the second disk, and so on. If instead you access the volume
element with much larger reads and writes (at least N*S), XLV will be
able to split up your request on these stripe boundaries and execute
the pieces in parallel on each disk. This gives you up to an N-fold
throughput improvement over one disk. You choose S, the volume
element's stripe unit, when you create the volume
element. In order to get the speedup, you must choose an appropriate
stripe unit and I/O size for striped volume elements, as explained
elsewhere in this document.
At the next layer up, you concatenate the address
range of one or more volume elements into the address range of a
plex, as is done within the data subvolume in the
diagram above. This performs a function very similar to
multipartition volume elements, but one level higher. For example, if
you are using striping and you want to create a volume that is larger
than any individual striped volume element, you can concatenate
several volume elements together into a plex by mapping them
contiguously into the plex's address range.
Then you specify one or more plexes for a logical
subvolume. The plex (also called the
mirror) is the level of redundancy. The diagram
above includes a logical subvolume (the log subvolume in this case)
with two plexes, meaning anything written to the logical subvolume
will be replicated in each plex for reliability. For our purposes, a
logical subvolume's address range is the same as that of each of its
plexes. If you have a logical subvolume with more than one plex, XLV
sometimes lets you use plexes with "holes" in their address range that
do not map to any volume element, but this is beyond the scope of this
document.
The logical subvolume is the highest level of addressible object in
XLV. A logical volume is a collection of separately
addressed subvolumes, consisting of a data subvolume,
an optional real-time subvolume, and an optional
log subvolume. These subvolumes are like three
different files: they have independent sizes and address ranges and
are not logically concatenated, striped, or replicated. We'll
describe the purpose of these subvolumes below.
This document makes the following simplifying assumptions about your
XLV setup:
- Each of your logical subvolumes has one plex that encompasses the
entire subvolume. Therefore your volume has no redundancy.
- Each of your plexes has one or more concatenated volume elements
that cover the entire range of the plex with no holes.
- Each of your volume elements consists of either a single partition,
or several partitions striped together. There's no real need to
discuss multipartition volume elements.
Accessing Partitions and Logical Volumes
When you access disks from IRIX tools or your program, you access
either partitions or logical volumes. There are two ways you can
access either of these objects:
- Normally you use mkfs to create an XFS filesystem
on the partition or logical volume, specifying the device
file for the partition (/dev/dsk/dks*) or logical volume
(/dev/dsk/xlv/*). Then you mount the filesystem (again providing the
device file) and use it.
- You can also open the raw device file for the
partition (/dev/rdsk/dks*) or logical volume (/dev/rdsk/xlv/*) and
directly read() and write() its raw bits. Some video applications
choose this option because they want to roll their own filesystem.
When you access an XLV logical volume with the raw device file, you
are accessing the data subvolume. There is not currently a way to
access the log or real-time subvolumes of an XLV volume with a raw
device file. Whenever you access a raw device file, you must follow
certain disk alignment, memory alignment, and I/O size rules. We'll
go over those in Software Methods for
Disk I/O.
This document assumes that your application accesses one filesystem or
one raw device file to do its video I/O.
XFS Filesystems
An XFS filesystem has three separately addressed sections: a log
section, a data section, and an optional real-time section.
- When you create an XFS filesystem on a single partition, mkfs
divides the partition into two parts and uses one for the log section
and one for the data section (this is called an internal
log). Filesystems on single partitions never have real-time
sections.
- When you create an XFS filesystem on an XLV logical volume,
- mkfs creates the data section of the XFS filesystem on the
XLV data subvolume.
- mkfs creates a real-time section for the XFS filesystem on the
XLV real-time subvolume, if the subvolume is present.
- mkfs creates the log section of the XFS filesystem on the XLV log
subvolume, if the subvolume is present (this is called an
external log). Otherwise, mkfs creates the log
section alongside the data section in the XLV data subvolume (internal
log).
Here is more on the three sections:
- The data section contains file data and the
metadata normally associated with a UNIX filesystem (superblock,
inodes, directories, extent tables, ...).
- The optional real-time section is an alternate
place where you can store file data. Unless otherwise specified, this
document will assume that you have only a data and log section. The
real-time section:
- has different blocksize/extent properties which are often useful
for video disk I/O to a striped XLV volume. We'll discuss these
elsewhere in this document.
- contains no metadata; inode and extent information for a file in a
real-time section is stored in the filesystem's data section.
Therefore, the XLV real-time subvolume that contains the real-time
section may include disks on which you have disabled retries. This
provides a tradeoff between reliability (writes are unreliable, reads
can fail) and latency (the disk only ever tries a read or write once,
reducing the worst-case probabilistic command completion time) which is
important for some applications.
A file's data is either stored in the data section (the normal case)
or the real-time section. Creating files in the real-time section
requires specially written code (one or more XFS-specific fcntl()s).
Reading from, writing to, or accounting for those files (stat() and
statvfs()) also requires special code. Standard UNIX tools like ls,
df or du require special IRIX-specific flags to tell you about the
real-time section storage of a file. Very few current GUI tools can
robustly deal with files in the real-time section.
- As you make changes to your filesystem that require updates to the
filesystem metadata, XFS makes a low-bandwidth log of those changes in
the log section. This log greatly increases the speed
and likelihood of recovering your filesystem if your machine crashes
(the log is why fsck is no more). XFS lazily updates the real
metadata in the data section based on the changes described in the log
section.
If you need to stripe disks together to get enough bandwidth to read
and write uncompressed video, you want to create striped volume
elements in either the data or real-time subvolumes of your XLV
logical volume, since that is where your file data will get stored
when you create an XFS filesystem on the XLV logical volume.