
The major video signals used in the world today are field-based, not frame based. Whenever you deal with video, it is absolutely crucial that you understand a few basic facts about fields. Correctly dealing with fields in software is tricky; it is fundamentally different than dealing with plain ol' graphics images. This document explains many of these basic concepts.
Note that the information here applies to any video signal format that has two interlaced fields per frame, including all of the major video signal formats which SGI machines deal with: NTSC, PAL, and 525- and 625-line Rec. 601 digital video (often incorrectly referred to as "D1").
Important: this document will give you a general understanding of the programming issues brought out by field-based video. But before you can go and write some code, it is also crucial that you understand the basic terms used to describe fields in our documentation and our library APIs. So after you read this, read:
An illustration. Pretend you have a film camera that can take 60 pictures per second. Say you use that camera to take a picture of a ball whizzing by the field of view. Here are 10 pictures from that sequence:
The time delay between each picture is a 60th of a second, so this sequence lasts 1/6th of a second.
Now say you take a modern* NTSC video camera and shoot the same sequence. We all know that NTSC video is 60 fields a second, so you might think that the video camera would record the same as the above. This is incorrect. The video camera does record 60 images per second, but each image consists of only half of the scanlines of the complete picture at a given time, like this:
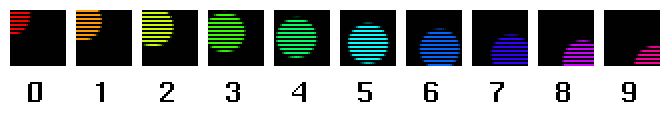
Note that the odd-numbered images contain one set of lines, and the even-numbered images contain the other set of lines (if you can't see this, try bringing up snoop or mag). The data captured by the video camera does not look like this:

and it does not look like this:
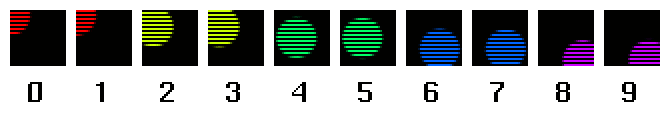
The fields captured are all temporally different. The harsh reality of video is that in any video sequence, you are missing half of the spatial information for every temporal instant. This is what we mean when we say "video is not frames." In fact, the notion of video as "frames" is something we computer people made up so as not to go insane---but sooner or later, we have to face the fact...
Say you want to take a video sequence which you have recorded (perhaps as uncompressed, or perhaps as JPEG-compressed data) and you want to show a still frame of this sequence. Well, a still frame would require a complete set of spatial information at a single instant of time---the data is simply not available to do a still frame correctly. So, one thing that much of our software does today to deal with this problem (and this is often done without knowledge of the real issue at hand), is to choose two adjacent fields from which to grab each set of lines. This technique has the rather ugly problem shown below:
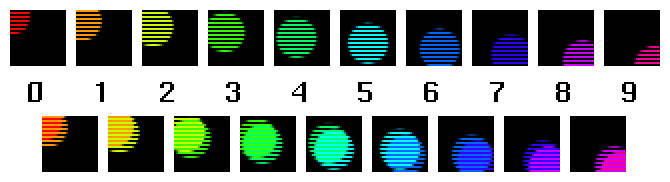
Nomatter which pair of fields you choose, the resulting still frame looks quite bad. This artifact, known as "tearing" or "fingering," is an inevitable consequence of putting together an image from bits of images snapped at different times. You wouldn't notice the artifact if the fields whizzed past your eye at field rate, but as soon as you try and do a freeze frame, the effect is highly visible and bad. You also wouldn't notice the artifact if the objects being captured were not moving between fields.
There's another thing about these fingering artifacts which we've often ignored in our software---they are terrible for most compressors. If you are making still frames so that you can pass frame-sized images on to a compressor, you definitely want to avoid tearing at all costs. The compressor will waste lots of bits trying to encode the high-frequency information in the tearing artifacts and fewer bits encoding your actual picture. Depending on what size and quality of compressed image you will end up with, you might even consider just sending every other field (perhaps decimated horizontally) to the compressor, rather than trying to create frames that will compress well.
Another possible technique for producing still-frames is to choose some field and double the lines in that field:

As you can see, this looks a little better, but there is an obvious loss of spatial resolution (ie, there's lots of jaggies and vertical blockiness now visible. To some extent, this can be reduced by interpolating adjacent lines in one field to get the lines of the other field:

But there is also a more subtle problem with any technique that uses one field only, which we'll see later.
There are an endless variety of more elaborate tricks you can use to come up with good still frames, all of which come under the heading of "de-interlacing methods." Some of these tricks attempt to use data from both fields in areas of the image that are not moving (so you get high spatial resolution), and double or interpolate lines of one field in areas of the image that are moving (so you get high temporal resolution). Many of the tricks take more than two fields as input. Since the data is simply not available to produce a spatially complete picture for one instant, there is no perfect solution. But depending on why you want the still frame, the extra effort may well be worth it.
So if that's true, then how come video images don't flicker hideously or jump up and down as alternate fields are refreshed?
This is partially explained by the persistence of the phosphors on the screen. Once refreshed, the lines of a given field start to fade out slowly, and so the monitor is still emitting some light from those lines when the lines of the other field are being refreshed. The lack of flicker is also partially explained by a similar persistence in your visual system.
Unfortunately though, these are not the only factors. Much of the reason why you do not perceive flicker on a video screen is that good-looking video signals themselves have built-in characteristics that reduce the visibility of flicker. It is important to understand these characteristics, because when you synthesize images on a computer or process digitized images, you must produce an image that also has these characteristics. An image which looks good on a non-interlaced computer monitor can easily look abysmal on an interlaced video monitor.
Disclaimer: a complete understanding of when flicker is likely to be perceivable and how to get rid of it requires an in-depth analysis of the properties of the phosphors of a particular monitor (not only their persistence but also their size, overlap, and average viewing distance), it requires more knowledge of the human visual system, and it may also require an in-depth analysis of the source of the video (for example, the persistence, size, and overlap of the CCD elements used in the camera, the shape of the camera's aperture, etc.). This description is only intended to give a general sense of the issues.
Disclaimer 2: standard analog video (NTSC and PAL) is fraught with design "features" (bandwidth limitations, etc.) which can introduce many similar artifacts to the ones we are describing here into the final result of video output from a computer. These artifacts are beyond the scope of this document, but are also important to consider when creating data to be converted to an analog video signal. Examples of this would be antialiasing (blurring!) data in a computer to avoid chroma aliasing when the data is converted to analog video.
Here are some of the major gotchas to worry about when creating data for video output:

Since the non-black data is contained on only one line, it will appear in only one field. A video monitor will only update the image of the line 30 times a second, and it will flicker on and off quite visibly. To see this on a video-capable machine, run "videoout," turn off the anti-flicker-filter, and point videoout's screen window at the image above.
You do not have to have a long line for this effect to be visible: thin, non-antialiased text exhibits the same objectionable flicker.
Typical video images are more vertically blurry; even where there is a sharp vertical transition (the bottom of an object in sharp focus, for example), the method typical cameras use to capture the image will cause the transition to blur over more than one line. It is often necessary to simulate this blurring when creating synthetic images for video.

These lines would include data in both fields, so part of the line is updated each 50th or 60th of a second. Unfortunately, when you actually look at the image of this line on a video monitor, the line appears to be solid in time, but it appears to jump up and down, as the top and bottom line alternate between being brighter and darker. You can also see this with the "videoout" program.
There is no particular magic method that will produce flicker-free video. The more you understand about the display devices you care about, and about when the human vision system perceives flicker and when it does not, the better a job you can do at producing a good image.
You might think that you could generate synthetic video by taking the output of a frame-based renderer at 25/30 frames per second and pulling two fields out of each frame image. This will not work well: the motion in the resulting sequence on an interlaced video monitor will noticeably stutter, due to the fact that the two fields are scanned out at different times, yet represent an image from a single time. Your renderer must know that it is rendering 50/60 temporally distinct images per second.
When fields enter the picture, things get ugly. Say you are playing a video sequence, and run up against a missing field (the issues we are discussing also come up when you wish to play back video slowly). You wish to keep the playback rate of the video sequence constant, so you have to put some video data in that slot:
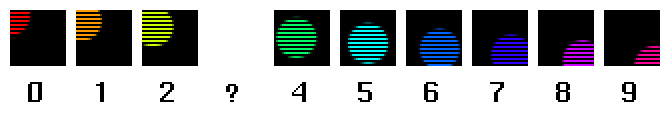
which field do you choose? Say you chose to duplicate the previous field, field 2:
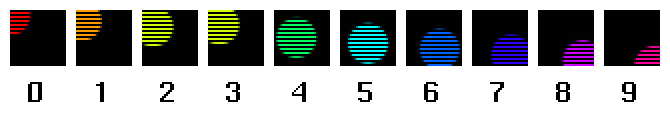
You could also try duplicating field 4 or interpolating between 2 and 4. But with all of these methods there is a crucial problem: those fields contain data from a different spatial location than the missing field. If you viewed the resulting video, you would immediately notice that the image visually jumps up and down at this point. This is a large-scale version of the same problem that made the two-pixel-high line jump up and down: your eye is very good at picking up on the vertical "motion" caused by an image being drawn to the lines of one field, then being drawn again one picture line higher, into the lines of the other field. Note that you would see this even if the ball was not in motion.
Ok, so you respond to this by instead choosing to fill in the missing field with the last non-missing field that occupies the same spatial locations:
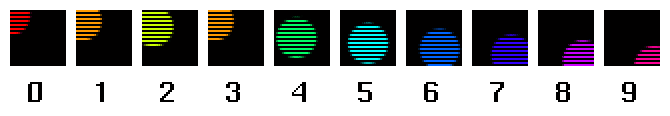
Now you have a more obvious problem: you are displaying the images temporally out of order. The ball appears to fly down, fly up again for a bit, and then fly down. Clearly, this method is no good for video which contains motion. But for video containing little or no motion, it would work pretty well, and would not suffer the up-and-down jittering of the above approach.
Which of these two methods is best thus depends on the video being used. For general-purpose video where motion is common, you'd be better off using the first technique, the "temporally correct" technique. For certain situations such as computer screen capture or video footage of still scenes, however, you can often get guarantees that the underlying image is not changing, and the second technique, the "spatially correct" technique, is a win.
As with de-interlacing methods, there are tons of more elaborate methods for interpolating fields which use more of the input data. For example, you could interpolate 2 and 4 and then interpolate the result of that vertically to guess at the content of the other field's lines. Depending on the situation, these techniques may or may not be worth the effort.
If you choose the "temporally correct" method and repeatedly output one field (effectively giving you the "line-doubled" look described above), then you get an image with reduced vertical resolution. But you also get another problem: as soon as you pause, the image appears to jump up or down, because your eye picks up on an image being drawn into the lines of one field, and then being drawn one picture line higher or lower, into the lines of another field. Depending on the monitor and other factors, the paused image may appear to jump up and down constantly or it may only appear to jump when you enter and exit pause.
If you choose the "spatially correct" method and repeatedly output a pair of fields, then if there happened to be any motion at the instant where you paused, you will see that motion happening back and forth, 60 times a second. This can be very distracting.
There are, of course, more elaborate heuristics that can be used to produce good looking pauses. For example, vertically interpolating an F1 to make an F2 or vice versa works well for slow-motion, pause, and vari-speed play. In addition, it can be combined with inter-field interpolation for "super slow-mo" effects.
The simplest method is to use the VL to capture already-interleaved frames, and display each frame on the screen at 25/30 per second using lrectwrite() or glDrawPixels(). Displaying In-Memory Video Using OpenGL provides some tips and code samples for this method.
While this looks okay, it does not look like a video monitor does. A video monitor is "interlaced." It scans across the entire screen, refreshing one field at a time, every 50th or 60th of a second. A typical graphics monitor is "progressive scan." It scans across the entire screen, refreshing every line of the picture, generally 50, 60, 72, or 76 times a second. Because graphics monitors are designed to refresh more often, their phosphors have a much shorter persistence than those of a video monitor.
If you viewed a video monitor in slow motion, you'd see a two-part pattern repeating 25 or 30 times a second: you'd see one field's lines light up brightly while the other field is fading out, then a 50th or a 60th of a second later, you'd see the other field's lines light up brightly while the first field's lines were fading out, as seen in this diagram:*
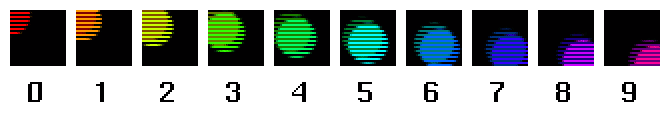
On a computer monitor running at 50 or 60 Hz, using the simple frame-based technique described above, you'd see a full-screen pattern repeating 50 or 60 times a second. The entire video image (the lines from both fields) light up and fade out uniformly, as in:*
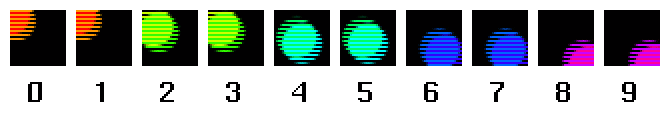
These differences in the slow-motion view can lead to noticeable differences when viewed at full-rate. Some applications demand that preview on the graphics screen look as much like the actual view on a monitor as possible, including (especially) the jitter effects associated with using fields incorrectly. Customers want to avoid having to buy an external monitor to verify whether or not their images will look ok on interlaced video.
Making video on a graphics monitor look like video is no easy task. Essentially, you have to create some software or hardware which will simulate the light which a video monitor would emit using the pixels of a graphics monitor.
So far, SGI has come up with two solutions to this problem:
These windows are most useful when the graphics frame rate is 50/60 frames per second (especially when graphics is genlocked with video). The windows change their appearance whenever a new field arrives from the video jack. The image which is actually displayed on the graphics monitor contains the image data from the field which just came in, on the proper lines for that field. What is displayed on the lines of the other field can be either:
These options provide two rough approximations to the appearance of an actual monitor. You would choose black on the theory that the graphics monitor's persistence was close enough to that of a video monitor. You would choose an interpolated signal (a very rough approximation to faded-out phosphors on the lines of the previous field) on the theory that the graphics monitor's persistence was not close enough.
Of course, this method does not simulate the decay of the phosphors that are not being updated on each draw. You can also choose to clear the framebuffer between draws, which would be similar to the black option of ev1/ev3 above. Check out Displaying In-Memory Video Using OpenGL for some code examples of the interlace extension. This extension can also be used to load texture memory on InfiniteReality.
The answer to this depends on the kind of camera. Modern cameras use CCD arrays, which produce a field of data by sampling the light incident on a grid of sensors (throughout a certain exposure time) simultaneously. Therefore all of the pixels of a field are coincident: each pixel is a sampling of the light from a particular part the scene during the same, finite period of time.
Older tube-based cameras (which were distinguished by crusty old names like vidicon and plumbicon) would sample a scene by scanning through that scene in much the same way a video monitor scans across its tube. Therefore, in the fields created by such a camera, none of the data is coincident! Instead of capturing the crispy images which we presented to you above:
A tube camera would capture an image more like this:

Tube cameras are dinosaurs and are being replaced by CCD-based cameras everywhere. But it is still quite possible that you'd run into one or possibly even be asked to write software to deal with video data from one.
When considering questions like how to photograph or videotape a computer monitor using a camera, this harsh reality can come into play.
However, because most of the flickering effects in interlaced video are due to local phenomena (ie, the appearance of data on adjacent picture lines), and because the temporal difference between samples on adjacent picture lines is so close to the field period, it is often the case that you don't have to worry about this harsh reality.
It's worth your while to check out:
to see the definitions and save yourself some headaches.
3:2 pulldown is a method of going between photographic film images at 24 frames per second and interlaced video images at 60 fields per second. It does not apply to 50-field-per-second signals. The method consists of a sequence which repeats every 4 film frames and 5 video frames (this chart assumes F1 dominance):
| Film Frames | frame A | frame B | frame C | frame D | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Video Fields | F1 | F2 | F1 | F2 | F1 | F2 | F1 | F2 | F1 | F2 |
| Video Frames | frame 1 | frame 2 | frame 3 | frame 4 | frame 5 | |||||
The lurkers guess that it's called 3:2 pulldown because the pattern of fields you get contains sequences of 3 fields followed by 2. Or perhaps it's called that because 3 of the 5 video frames do not end up coinciding with the start of a film frame and 2 do.